
티스토리 뷰
Going deeper with convolutions (GoogLeNET) - Architectural Details
provbs 2023. 6. 14. 10:54chat gpt의 도움을 받아 작성하였습니다
4 Architectural Details
The main idea of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered by readily available dense components.
Inception 아키텍처의 주요 아이디어는, 컨볼루션 비전 네트워크에서 최적의 지역적 희소 구조를 어떻게 근사화하고, 이를 이용할 수 있는 밀집 구성 요소로 대체할 수 있는지를 찾는 것입니다.
Note that assuming translation invariance means that our network will be built from convolutional building blocks. All we need is to find the optimal local construction and to repeat it spatially.
번역 불변성을 가정하는 것은 우리의 네트워크가 컨볼루션 구성 요소로 구성될 것을 의미합니다. 우리가 필요한 것은 최적의 지역적 구성을 찾아서 이를 공간적으로 반복하는 것뿐입니다
Arora et al. [2] suggests a layer-by layer construction in which one should analyze the correlation statistics of the last layer and cluster them into groups of units with high correlation.
Arora et al. [2] 제안에 따르면, 레이어별로 구성을 진행해야 합니다. 이를 위해서는 마지막 레이어의 상관관계 통계를 분석하고, 상관관계가 높은 유닛들을 그룹으로 묶어야 합니다.
These clusters form the units of the next layer and are connected to the units in the previous layer.
이러한 클러스터는 다음 레이어의 유닛들을 형성하며, 이전 레이어의 유닛들과 연결됩니다. 클러스터링은 유사한 특성을 가진 유닛들을 그룹으로 묶는 과정을 말하며, 이를 통해 네트워크의 구조가 형성됩니다. 이러한 연결 구조를 통해 정보의 흐름이 전달되며, 네트워크는 효율적이고 정확한 패턴 인식을 수행할 수 있게 됩니다.
We assume that each unit from the earlier layer corresponds to some region of the input image and these units are grouped into filter banks.
In the lower layers (the ones close to the input) correlated units would concentrate in local regions.
Inception 아키텍처에서는 이전 레이어의 각 유닛이 입력 이미지의 특정 영역 또는 수용 영역에 해당한다고 가정합니다. 이러한 유닛은 필터 뱅크로 그룹화됩니다. 필터 뱅크는 입력에서 다른 특징이나 패턴을 감지하는데 역할을 하는 유닛의 모음입니다. (필터 뱅크 - 필터들의 집합)
입력에 가까운 하위 레이어에서는 높은 상관관계를 가진 유닛들이 지역적으로 집중될 것으로 예상됩니다. 이는 특정 필터 뱅크 내의 유닛들이 해당 수용 영역에서 유사한 활성화 패턴을 보일 가능성이 높다는 것을 의미합니다.
This means, we would end up with a lot of clusters concentrated in a single region and they can be covered by a layer of 1×1 convolutions in the next layer, as suggested in [12].
이는 결과적으로 하나의 지역에 집중된 많은 클러스터가 형성될 것이며, 다음 레이어에서 [12]에서 제안된 대로 1×1 컨볼루션 레이어로 해당 클러스터들을 다룰 수 있게 될 것을 의미합니다.
1×1 컨볼루션은 공간적인 차원 축소 및 차원 변환을 수행하는 데 사용됩니다. 이를 통해 클러스터의 정보를 압축하고, 다음 레이어로 전달될 수 있는 더 작은 특성 맵을 생성할 수 있습니다. 이러한 방식으로 Inception 아키텍처는 효율적인 표현력과 계산 효율성을 동시에 달성할 수 있습니다.
However, one can also expect that there will be a smaller number of more spatially spread out clusters that can be covered by convolutions over larger patches, and there will be a decreasing number of patches over larger and larger regions.
하지만, 더 공간적으로 분포된 작은 수의 클러스터가 존재하며, 이들은 더 큰 패치 위에서의 컨볼루션을 통해 다룰 수 있을 것으로 기대할 수 있습니다. 또한, 점점 더 큰 영역에 대해 패치의 수가 감소할 것입니다.
클러스터의 크기와 위치에 따라 컨볼루션을 적용할 수 있는데, 작은 클러스터는 작은 패치 위에서 컨볼루션을 수행함으로써 해당 영역을 다룰 수 있습니다. 더 큰 영역에 대해서는 더 큰 패치 위에서 컨볼루션을 수행하여 이를 처리할 수 있습니다.
이러한 다양한 컨볼루션 연산은 다양한 영역의 특징을 효과적으로 잡아내고 추출할 수 있도록 도와줍니다. Inception 아키텍처는 이러한 다양한 스케일의 특징을 포착하는 데에 탁월한 성능을 발휘하며, 네트워크의 표현력을 향상시킵니다.
In order to avoid patchalignment issues, current incarnations of the Inception architecture are restricted to filter sizes 1×1, 3×3 and 5×5, however this decision was based more on convenience rather than necessity.
현재의 Inception 아키텍처는 패치 정렬 문제를 피하기 위해 1×1, 3×3, 5×5 크기의 필터만을 사용합니다. 그러나 이러한 결정은 편의를 위한 것이 필수적인 선택은 아닙니다.
패치 정렬 문제란, 다양한 크기의 필터를 사용할 때, 필터 크기에 따라 입력 이미지의 픽셀과 필터의 중심 위치 간에 정렬이 잘 이루어지지 않는 문제를 의미합니다. 이는 필터 크기에 따라 필터의 중심 위치가 픽셀과 정렬되지 않을 경우, 원하는 특징을 적절하게 추출하지 못하거나 정보의 손실을 야기할 수 있습니다.
따라서 Inception 아키텍처에서는 일부 필터 크기를 제한함으로써 이러한 패치 정렬 문제를 해결하려고 합니다. 1×1, 3×3, 5×5 크기의 필터는 다양한 스케일의 특징을 잘 포착할 수 있는 크기로 선택되었고, 이를 통해 효과적인 특징 추출과 네트워크의 성능 향상을 이루어낼 수 있습니다.
이러한 선택은 주로 편의성과 구현상의 이점을 고려하여 이루어진 것입니다. 특정 필터 크기가 절대적으로 필요하다기보다는, 사용자가 효과적이고 효율적인 네트워크 구성을 쉽게 구현하고 조정할 수 있도록 하는 목적으로 결정된 것입니다.
It also means that the suggested architecture is a combination of all those layers with their output filter banks concatenated into a single output vector forming the input of the next stage.
이는 제안된 아키텍처가 모든 이러한 레이어를 조합한 것이며, 각 레이어의 출력 필터 뱅크를 하나의 출력 벡터로 연결하여 다음 단계의 입력으로 사용한다는 것을 의미합니다.
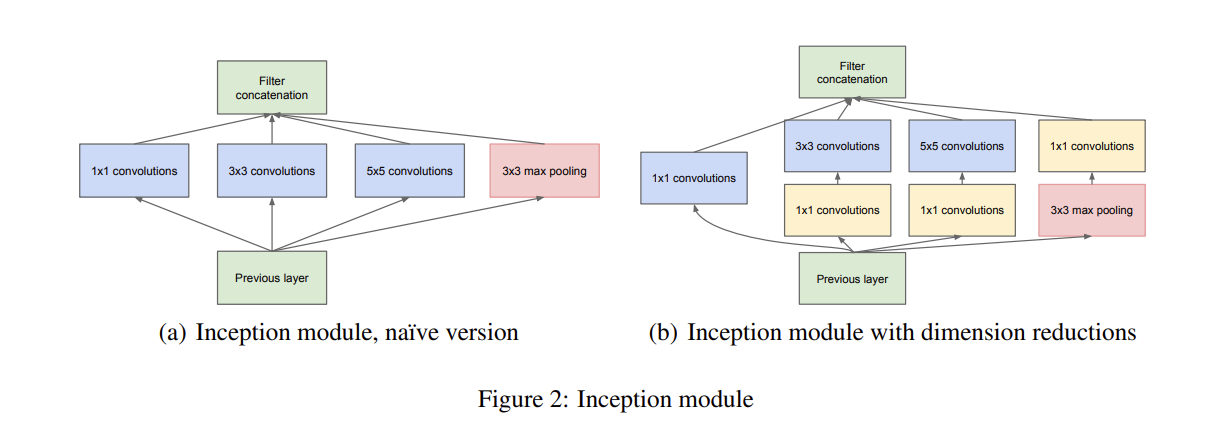
Additionally, since pooling operations have been essential for the success in current state of the art convolutional networks, it suggests that adding an alternative parallel pooling path in each such stage should have additional beneficial effect, too (see Figure 2(a)).
추가로, 현재 최첨단 합성곱 신경망에서 풀링 연산은 성능에 중요한 역할을 합니다. 이러한 이유로, 각 단계마다 대체로 사용되는 병렬 풀링 경로를 추가하는 것도 추가적인 이점을 가져올 수 있습니다 (그림 2(a) 참조).
As these “Inception modules” are stacked on top of each other, their output correlation statistics are bound to vary: as features of higher abstraction are captured by higher layers, their spatial concentration is expected to decrease suggesting that the ratio of 3×3 and 5×5 convolutions should increase as we move to higher layers.
"Inception modules"는 서로 쌓이면서 그들의 출력 상관 통계가 달라질 것으로 예상됩니다. 더 높은 계층에서는 더 높은 추상화 수준의 특징이 포착되기 때문에, 공간적인 집중도는 감소할 것으로 예상됩니다. 이는 더 높은 계층으로 이동할수록 3×3 및 5×5 컨볼루션의 비율이 증가해야 함을 시사합니다.
One big problem with the above modules, at least in this na¨ıve form, is that even a modest number of 5×5 convolutions can be prohibitively expensive on top of a convolutional layer with a large number of filters.
위에서 설명한 모듈들의 큰 문제 중 하나는, 특히 큰 수의 필터를 가진 컨볼루션 레이어 위에 5×5 컨볼루션을 사용하는 것은 계산 비용이 매우 크다는 것입니다.
This problem becomes even more pronounced once pooling units are added to the mix: their number of output filters equals to the number of filters in the previous stage.
이 문제는 풀링 유닛이 추가되면 더욱 두드러집니다: 풀링 유닛의 출력 필터 수는 이전 단계의 필터 수와 동일합니다.
풀링 유닛을 추가하면서 필터 수가 증가하면, 5×5 컨볼루션의 계산 비용이 더욱 증가하게 됩니다. 이는 연산 부담을 크게 키울 수 있으며, 특히 필터 수가 많은 네트워크에서는 심각한 문제가 될 수 있습니다
The merging of the output of the pooling layer with the outputs of convolutional layers would lead to an inevitable 4 1x1 convolutions 3x3 convolutions 5x5 convolutions Filter concatenation Previous layer 3x3 max pooling (a) Inception module, na¨ıve version 1x1 convolutions 3x3 convolutions 5x5 convolutions Filter concatenation Previous layer 1x1 convolutions 1x1 convolutions 3x3 max pooling 1x1 convolutions (b) Inception module with dimension reductions Figure 2: Inception module increase in the number of outputs from stage to stage.
풀링 레이어의 출력을 컨볼루션 레이어의 출력과 병합하는 것은 피할 수 없이 1x1, 3x3, 5x5 컨볼루션에 대한 4개의 계산을 유발합니다. 이러한 계산은 필터를 이전 레이어의 출력과 연결하고, 3x3 최대 풀링과 같은 작업을 수행하는 Inception 모듈에서 사용됩니다. 이러한 Inception 모듈은 단계별로 출력의 수가 증가함에 따라 1x1, 3x3, 5x5 컨볼루션에 대한 필터 연결이 늘어나는 것을 확인할 수 있습니다.
그림 2에서 (a)는 초기 버전의 Inception 모듈이며, (b)는 차원 축소 기능이 추가된 Inception 모듈입니다.
Even while this architecture might cover the optimal sparse structure, it would do it very inefficiently, leading to a computational blow up within a few stages.
이 아키텍처는 optimal sparse 구조를 다룰 수는 있지만, 몇 단계 내에서 계산적으로 매우 비효율적인 결과를 가져올 수 있습니다. 이는 계산 부하가 증가하는 현상을 야기할 수 있습니다.
This leads to the second idea of the proposed architecture: judiciously applying dimension reductions and projections wherever the computational requirements would increase too much otherwise.
이로 인해 제안된 아키텍처의 두 번째 아이디어가 등장합니다. 계산 요구사항이 너무 많이 증가할 경우, 계산 비용을 감소시키기 위해 차원 축소와 투영을 적절하게 적용하는 것입니다.
This is based on the success of embeddings: even low dimensional embeddings might contain a lot of information about a relatively large image patch.
이는 임베딩의 성공에 기반합니다. 심지어 낮은 차원의 임베딩은 비교적 큰 이미지 패치에 대한 많은 정보를 포함할 수 있습니다.
"Embeddings"는 일반적으로 저차원 벡터 공간으로의 매핑을 의미합니다. 컴퓨터 비전에서 이미지나 텍스트와 같은 고차원 데이터를 저차원의 잠재 공간으로 투영하는 기법을 의미하기도 합니다. 이러한 잠재 공간 표현은 데이터의 의미와 특성을 보존하면서 차원 축소와 압축을 통해 데이터를 효율적으로 표현할 수 있게 합니다.
However, embeddings represent information in a dense, compressed form and compressed information is harder to model.
하지만, 임베딩은 정보를 밀집하고 압축된 형태로 나타내기 때문에, 압축된 정보는 모델링하기가 더 어렵습니다.
We would like to keep our representation sparse at most places (as required by the conditions of [2]) and compress the signals only whenever they have to be aggregated en masse.
우리는 대부분의 위치에서 표현을 sparse하게 유지하고 싶습니다 ([2]의 조건에 따라 필요합니다) 그리고 신호를 대량으로 집계해야 할 때에만 압축하고 싶습니다.
That is, 1×1 convolutions are used to compute reductions before the expensive 3×3 and 5×5 convolutions. Besides being used as reductions, they also include the use of rectified linear activation which makes them dual-purpose.
1×1 컨볼루션은 비용이 많이 드는 3×3 및 5×5 컨볼루션을 수행하기 전에 차원을 줄이는 데 사용됩니다. 이러한 1×1 컨볼루션은 차원 축소 용도로 사용되는 것뿐만 아니라, rectified linear activation 함수를 포함하여 두 가지 목적으로 사용됩니다.
The final result is depicted in Figure 2(b).
Figure 2(b)는 제안된 아키텍처의 최종 결과를 보여줍니다.
In general, an Inception network is a network consisting of modules of the above type stacked upon each other, with occasional max-pooling layers with stride 2 to halve the resolution of the grid.
일반적으로, Inception 네트워크는 위에서 설명한 유형의 모듈을 쌓아 올린 형태의 네트워크로 구성됩니다. 이 네트워크는 때때로 stride 2로 설정된 max-pooling 레이어를 포함하며, 그리드의 해상도를 절반으로 줄입니다. 이를 통해 네트워크는 점진적으로 더 깊어지고 복잡한 특징을 학습할 수 있게 됩니다.
For technical reasons (memory efficiency during training), it seemed beneficial to start using Inception modules only at higher layers while keeping the lower layers in traditional convolutional fashion.
기술적인 이유(학습 중의 메모리 효율성)로 인해, 하위 레이어는 전통적인 합성곱 방식으로 유지하면서 Inception 모듈을 더 높은 레이어에서 사용하는 것이 이득으로 보였습니다. 이렇게 함으로써 네트워크는 기존의 합성곱 레이어로 저수준의 특징을 추출하고, Inception 모듈을 통해 고수준의 추상화된 특징을 학습할 수 있습니다. 이러한 접근 방식은 학습 및 메모리 사용 측면에서 효율적인 결과를 가져올 수 있습니다.
This is not strictly necessary, simply reflecting some infrastructural inefficiencies in our current implementation.
이는 엄격히 필요한 것은 아니며, 현재 구현에서 인프라적인 비효율성을 반영한 것입니다. 다른 구현 방식이나 개선된 인프라를 사용한다면 이러한 제한은 필요하지 않을 수 있습니다. 즉, 현재의 제한은 구현 환경에 따른 것이며, 더 나은 구현 방식이나 업데이트된 인프라를 통해 이러한 제한을 극복할 수 있습니다.
One of the main beneficial aspects of this architecture is that it allows for increasing the number of units at each stage significantly without an uncontrolled blow-up in computational complexity.
이 아키텍처의 주요 이점 중 하나는 계산 복잡성이 제어되지 않는 상황을 가지지 않으면서, 각 단계에서의 유닛 수를 크게 증가시킬 수 있다는 것입니다. 이는 계산 복잡성이 제한되지 않으면서도 네트워크의 용량을 확장할 수 있는 장점을 제공합니다. 즉, 모델의 용량을 증가시키는 데 있어서 효율적인 방법을 제공하여 더 많은 파라미터와 더 강력한 표현력을 확보할 수 있습니다.
The ubiquitous use of dimension reduction allows for shielding the large number of input filters of the last stage to the next layer, first reducing their dimension before convolving over them with a large patch size.
차원 축소의 보편적인 사용은 마지막 단계의 많은 입력 필터들을 다음 레이어로 보호하기 위해 가능하게 합니다. 이는 먼저 차원을 축소시키고 나서 큰 패치 크기로 이들을 컨벌루션하는 방식입니다. 이를 통해 많은 수의 입력 필터를 더 효율적으로 처리할 수 있으며, 더 넓은 수용 영역을 갖는 컨벌루션 연산을 수행할 수 있습니다. 이는 네트워크의 효율성을 향상시키고, 더 복잡하고 정교한 특징을 추출하는 데 도움이 됩니다.
-> 1x1 하고 난 뒤에 3x3이나 5x5를 하는 이유를 설명 (그렇게 해서 얻는 장점이 무엇인가?)
Another practically useful aspect of this design is that it aligns with the intuition that visual information should be processed at various scales and then aggregated so that the next stage can abstract features from different scales simultaneously.
이 디자인의 또 다른 실용적인 측면은 시각적 정보가 다양한 스케일에서 처리되고, 다음 단계에서 동시에 다른 스케일의 특징을 추상화할 수 있도록 집계되어야 한다는 직관과 일치한다는 것입니다. 이는 시각적인 세부 사항과 전반적인 구조를 모두 포착하면서도, 계층적인 방식으로 특징을 추출할 수 있는 장점을 제공합니다. 이는 객체의 크기나 형태에 상관없이 다양한 특징을 인식하고 분류하는 데 도움이 되며, 네트워크의 성능을 향상시킬 수 있습니다.
The improved use of computational resources allows for increasing both the width of each stage as well as the number of stages without getting into computational difficulties.
향상된 계산 리소스의 활용은 각 단계의 너비와 단계의 수를 늘릴 수 있게 해주며, 계산에 어려움을 겪지 않고 증가할 수 있도록 합니다. 이는 더 많은 필터와 더 깊은 구조를 가진 네트워크를 구성할 수 있어서, 모델의 용량과 표현력을 늘릴 수 있는 장점을 제공합니다. 이를 통해 더 복잡하고 정교한 시각적인 작업을 수행할 수 있으며, 모델의 성능과 정확도를 향상시킬 수 있습니다.
Another way to utilize the inception architecture is to create slightly inferior, but computationally cheaper versions of it.
Inception 아키텍처를 활용하는 또 다른 방법은 약간의 희생을 감수하면서도 계산 비용이 더 적은 버전을 생성하는 것입니다. 이는 모델의 복잡도와 계산 요구량을 조정하여 자원을 더 효율적으로 활용하는 방법입니다. 이를 통해 제한된 컴퓨팅 자원으로도 상당한 성능을 얻을 수 있습니다. 이러한 접근 방식은 예산이 제한된 환경이나 임베디드 시스템과 같이 계산 능력이 제한된 상황에서 유용하게 사용될 수 있습니다.
We have found that all the included the knobs and levers allow for a controlled balancing of computational resources that can result in networks that are 2 − 3× faster than similarly performing networks with non-Inception architecture, however this requires careful manual design at this point.
우리는 모든 조절 장치와 레버들이 계산 자원을 조절하는 데에 도움을 주며, 비슷한 성능을 내는 비-Inception 아키텍처와 비교했을 때 2배에서 3배 정도 더 빠른 네트워크를 구축할 수 있다는 것을 발견했습니다. 하지만 현재로서는 이를 위해서는 신중한 수동 설계가 필요합니다. 이것은 최적의 성능과 효율을 달성하기 위해 사용자가 직접 조정해야 하는 요소들이 많은 것을 의미합니다. 따라서 Inception 아키텍처를 활용하여 성능 향상과 계산 효율화를 동시에 이루는 것은 가능하지만, 그 과정은 현재로서는 주의 깊은 수작업 설계를 필요로 합니다.