티스토리 뷰
5 GoogLeNet
We chose GoogLeNet as our team-name in the ILSVRC14 competition.
This name is an homage to Yann LeCuns pioneering LeNet 5 network [10].
우리는 ILSVRC14 대회에서 팀 이름으로 "GoogLeNet"을 선택했습니다. 이 이름은 Yann LeCun의 선구적인 LeNet 5 네트워크에 대한 경의의 표현입니다 [10]. LeNet 5은 컨벌루션 신경망의 초기 모델 중 하나로 알려져 있으며, 딥러닝의 발전에 기여한 중요한 업적으로 평가받고 있습니다. "GoogLeNet"은 이러한 선구자적인 네트워크에 대한 경의와 구글(Google)의 참가를 결합한 이름입니다.
We also use GoogLeNet to refer to the particular incarnation of the Inception architecture used in our submission for the competition.
We have also used a deeper and wider Inception network, the quality of which was slightly inferior, but adding it to the ensemble seemed to improve the results marginally.
We omit the details of that network, since our experiments have shown that the influence of the exact architectural parameters is relatively minor.
우리는 또한 "GoogLeNet"을 대회 참가를 위해 사용한 Inception 아키텍처의 특정 버전을 가리키는 용어로 사용합니다.
또한 더 깊고 넓은 Inception 네트워크를 사용했는데, 이는 결과적으로 약간의 품질 저하를 가져왔지만, 이를 앙상블에 추가하면 결과가 약간 향상되는 것으로 나타났습니다.
우리는 정확한 아키텍처 매개변수의 영향이 상대적으로 미미하다는 것을 실험을 통해 확인했기 때문에, 해당 네트워크의 세부 사항은 생략합니다.

Here, the most successful particular instance (named GoogLeNet) is described in Table 1 for demonstrational purposes.
The exact same topology (trained with different sampling methods) was used for 6 out of the 7 models in our ensemble.
All the convolutions, including those inside the Inception modules, use rectified linear activation.
Table 1에서는 설명을 위해 가장 성공적인 특정 인스턴스인 "GoogLeNet"이 나와있습니다.
이 인스턴스의 정확히 동일한 토폴로지(다른 샘플링 방법으로 학습된)가 우리의 앙상블 중 7개 모델 중 6개에 사용되었습니다. 토폴로지 -> 망 구성 구조
인셉션 모듈 내부를 포함한 모든 컨볼루션은 ReLU(정류된 선형 활성화)를 사용합니다.
The size of the receptive field in our network is 224×224 taking RGB color channels with mean subtraction.
“#3×3 reduce” and “#5×5 reduce” stands for the number of 1×1 filters in the reduction layer used before the 3×3 and 5×5 convolutions.
One can see the number of 1×1 filters in the projection layer after the built-in max-pooling in the pool proj column.
우리 네트워크의 수용 영역 크기는 224×224이며, RGB 색상 채널을 사용했고, mean substraction으로 처리했습니다.
("Mean subtraction"은 이미지에 대해 평균 값을 뺀 것을 의미합니다. 이 과정은 입력 이미지에서 RGB 채널별로 평균 값을 계산하고 해당 평균 값을 각 픽셀에서 뺌으로써 수행됩니다. 이렇게 함으로써 입력 이미지의 평균이 0에 가까워지고 데이터의 중심이 원점에 가까워지는 효과를 얻을 수 있습니다. 이는 데이터의 분포를 정규화하고 모델의 학습을 돕는 전처리 단계입니다.)
"#3×3 reduce"와 "#5×5 reduce"는 3×3 및 5×5 컨볼루션 이전에 사용되는 축소 계층의 1×1 필터 수를 나타냅니다.
pool proj 열에서는 내장된 최대 풀링 이후의 투사 계층의 1×1 필터 수를 볼 수 있습니다. (max-pooling 이후의 1x1 필터 적용했었던 것)
All these reduction/projection layers use rectified linear activation as well.
The network was designed with computational efficiency and practicality in mind, so that inference can be run on individual devices including even those with limited computational resources, especially with low-memory footprint.
The network is 22 layers deep when counting only layers with parameters (or 27 layers if we also count pooling).
모든 reduction/projection 레이어는 rectified linear activation을 사용합니다. 이는 일반적으로 ReLU라고 알려진 활성화 함수로, 입력이 양수인 경우에는 그 값을 그대로 출력하고, 음수인 경우에는 0으로 출력하는 함수입니다.
GoogLeNet은 계산 효율성과 실용성을 고려하여 설계되었습니다. 이는 개별 장치에서 추론을 실행할 수 있도록 하며, 특히 메모리 제약이 있는 장치에서도 작동할 수 있도록 고려되었습니다. 낮은 메모리 풋프린트를 가진 장치에서도 사용 가능하도록 설계되었습니다.
네트워크는 매개변수를 가진 레이어만을 계산하여 22개의 레이어로 구성됩니다. 풀링을 포함한 경우 27개의 레이어로 구성됩니다. 이는 네트워크의 깊이를 나타내는 지표로 사용됩니다.
The overall number of layers (independent building blocks) used for the construction of the network is about 100.
However this number depends on the machine learning infrastructure system used. The use of average pooling before the classifier is based on [12], although our implementation differs in that we use an extra linear layer.
This enables adapting and fine-tuning our networks for other label sets easily, but it is mostly convenience and we do not expect it to have a major effect.
네트워크 구성에 사용되는 전체 레이어(독립적인 빌딩 블록)의 총 수는 약 100개입니다.
그러나 이 숫자는 사용하는 기계 학습 인프라 시스템에 따라 달라집니다. 분류기 이전에 평균 풀링을 사용하는 것은 [12]에 기반하였으나, 우리의 구현은 추가적인 선형 레이어를 사용하는 점에서 다릅니다.
이는 다른 라벨 집합에 대해 네트워크를 쉽게 적용하고 세밀하게 조정할 수 있도록 하는 장점을 가지고 있지만, 주로 편의를 위한 기능이며 큰 영향을 미치지 않을 것으로 예상됩니다.
It was found that a move from fully connected layers to average pooling improved the top-1 accuracy by about 0.6%, however the use of dropout remained essential even after removing the fully connected layers.
Given the relatively large depth of the network, the ability to propagate gradients back through all the layers in an effective manner was a concern.
One interesting insight is that the strong performance of relatively shallower networks on this task suggests that the features produced by the layers in the middle of the network should be very discriminative.
결과적으로 fully connected 레이어에서 average 풀링으로의 전환은 top-1 정확도를 약 0.6% 향상시켰습니다. 하지만 완전 연결 레이어를 제거한 후에도 드롭아웃 사용은 여전히 중요했습니다.
상대적으로 큰 깊이를 가진 네트워크의 경우, 효과적인 방식으로 모든 레이어를 통해 그래디언트를 전파하는 능력은 우려되었습니다.
또한, 이 작업에서 비교적 얕은 네트워크의 강력한 성능은 네트워크 중간 레이어에서 생성되는 피쳐가 매우 식별력이 있을 것으로 추정됩니다.
By adding auxiliary classifiers connected to these intermediate layers, we would expect to encourage discrimination in the lower stages in the classifier, increase the gradient signal that gets propagated back, and provide additional regularization.
These classifiers take the form of smaller convolutional networks put on top of the output of the Inception (4a) and (4d) modules.
During training, their loss gets added to the total loss of the network with a discount weight (the losses of the auxiliary classifiers were weighted by 0.3).
중간 레이어에 연결된 보조 분류기를 추가함으로써, 우리는 분류기의 하위 단계에서의 식별을 장려하고, 전파되는 그래디언트 신호를 증가시키며, 추가적인 정규화를 제공할 것으로 기대합니다.
이러한 분류기는 Inception (4a) 및 (4d) 모듈의 출력 위에 놓인 작은 컨볼루션 네트워크의 형태를 취합니다.
훈련 중에는 이들 분류기의 손실이 네트워크의 총 손실에 할인 가중치로 추가됩니다 (보조 분류기의 손실은 0.3으로 가중치가 적용되었습니다).
At inference time, these auxiliary networks are discarded. The exact structure of the extra network on the side, including the auxiliary classifier, is as follows:
• An average pooling layer with 5×5 filter size and stride 3, resulting in an 4×4×512 output for the (4a), and 4×4×528 for the (4d) stage.
• A 1×1 convolution with 128 filters for dimension reduction and rectified linear activation.
• A fully connected layer with 1024 units and rectified linear activation.
• A dropout layer with 70% ratio of dropped outputs.
• A linear layer with softmax loss as the classifier (predicting the same 1000 classes as the main classifier, but removed at inference time).
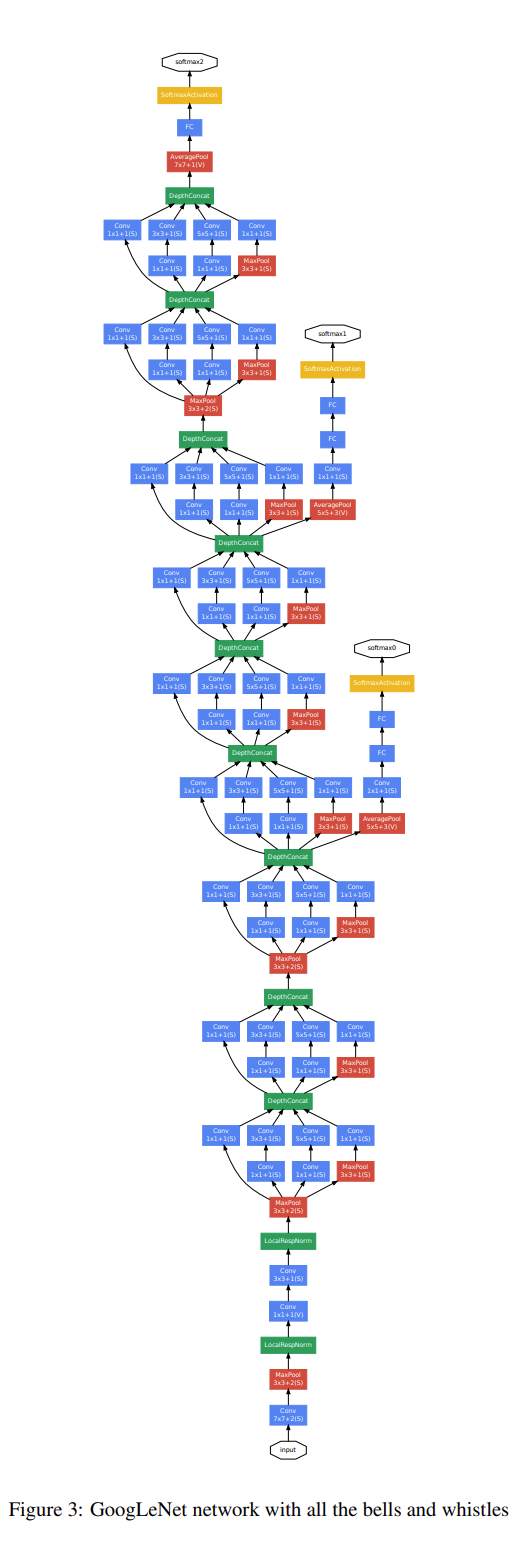
A schematic view of the resulting network is depicted in Figure 3.
추가적인 네트워크의 구조는 다음과 같습니다.
- 5×5 필터 크기와 스트라이드 3을 가진 평균 풀링 레이어. 이로 인해 (4a) 단계에는 4×4×512 출력이 생성되며, (4d) 단계에는 4×4×528 출력이 생성됩니다.
- 차원 축소와 ReLU 활성화를 위한 1×1 컨볼루션 레이어. 128개의 필터를 사용합니다.
- 1024개의 유닛과 ReLU 활성화를 가진 완전 연결 레이어.
- 70%의 비율로 출력을 제외하는 드롭아웃 레이어.
- 소프트맥스 손실을 가진 선형 레이어로 이루어진 분류기 (주 분류기와 동일한 1000개의 클래스를 예측하지만 추론 시 제거됩니다).
이러한 구조를 가진 네트워크의 도식적인 모습은 Figure 3에 나타내었습니다.